![[Translate to English:] Zur Startseite des SFB Farbige Zustände](/fileadmin/user_upload/sites/sfb1232/Logos_und_Bilder/SFB1232-quer.png)
P01 - Predictor - Function
Data modeling
An important contribution of the subproject P01 to the Collaborative Research Centre P01 concerns the data modeling of the experimental data sets. For this purpose, a central data infrastructure is required, which includes a global data model for all the sample generation and treatment (thermal, mechanical) processes as well as descriptor screenings (so-called process steps). In order to ensure the reproducibility of individual experiments in terms of good scientific practice, an individual formal specification of each process is necessary. The quantity of all processes includes all the processes that generate and treat the material as well as the descriptor screening and material property determination. Not only the experimental data itself but also the raw data and the process parameters are recorded. A library based on the common JavaScript Object Notation (JSON) has been developed for the formal specification, which allows good readability and which can be processed natively by the data input system.
This specification defines the data type or the value range of each individual process parameter, allowing a consistency check directly during the input. Another important functionality is the implementation of parser routines, which functionally realize the parsing, the preprocessing and the structured storage of research data.
Based on the formal specifications, individual input masks have been generated by the implemented web-based input system, which are used by the respective scientific staff or technicians to submit the experiments in the central database. The input system implements a role-based user model, whereby the access rights can be assigned restrictively and traceability in terms of data provenance is ensured. Furthermore, a liability between the author and the data sets is created.
In addition, a concept for versioning the process specifications has been developed to address the evolution of the individual processes. During the first funding phase, a total of 60 processes were specified, resulting in a cumulative total of 380 versions. These specifications were made in joint expert interviews in close cooperation with the working group "Data Exchange and Data Management". During the process of data modeling and interface design, the FAIR principles played an important role.
The database
Contrary to the widespread dissemination of SQL-based databases, a document-oriented database was consciously used. A classical SQL database system has a predefined table structure, which typically requires extensive merging operations (so-called JOINs) in the case of complex queries. These operations often form a massive bottleneck when processing large sets of data. If, on the other hand, the causal relationship and subsequent semantic usage are a-priori given, all coherent parts of the information can be saved directly in one single document and stored in the document-oriented database.
Since the investigations are strictly sample-oriented and the results of each process can be interpreted as an atomic unit, this semantic data context is well known in the Collaborative Research Centre 1232. The samples themselves are tagged using a newly developed, standardized scheme, which means that the individual samples, including their entire process history, will be directly addressable even during the process of the project. The use of this sample-oriented storage in combination with the document-oriented database system eliminates the need for holistic mergers and, hence, massively reduces the number of links in data storage or data access. In general, a document-oriented database is ideal for heterogeneous data records, since no fixed table structure exists that would have to be updated retroactively.
Two different classes were used in the developed, document-oriented data model: The first class models an atomic process step including all associated meta information, process parameters, and measurement data. The second class models a sample as an entity in the system, contains central attributes such as the unique sample ID, and also shows the process history in the form of a linear data structure (array). This array consists of a chronologically ordered sequence of process steps, whereby the corresponding process steps are only stored as a reference. Especially thermal treatment processes, as well as original forming processes (on the micro level), are applied simultaneously to a large number of samples. The use of references allows the parameters of the above-mentioned processes to be simply stored, thus enabling data deduplication. Furthermore, this structure allows the distinction between invasive and non-invasive processes: If the state of a sample is modifiedby a process step, a new (virtual) indentation is created and all subsequent process steps are associated with this modified state. This model allows easy access to all data sets associated with a single sample or a specific sample state.
The MongoDB (cf. www.mongodb.com) is used as the central database, which is characterized in particular by a good connectivity regarding a large number of relevant programming languages. Another important aspect was the efficient storage of the documents themselves, e.g. with the aid of data deduplication, which is made possible by MongoDB.
New basic operators for application-specific data access have been developed and made available to the other subprojects as a software library. The extensibility of the native command set of MongoDB was used to integrate a query framework directly into the database, which provides the required functionalities regarding the data query. These basic operators take into account not only the sample and process data but also the information from the formal specification of the individual processes.
For more information on the use of the database:
BigData-Insider: Bremen geht neue Wege in der Materialforschung (german-written text)
MongoDB-Blog: Creating the material world through data, one million inventions at a time
The expert knowledge
Additionally, further knowledge about the correlations - both at a coarse (process level) granularity and fine (level of characteristic values) granularity - is used in the basic operators. These correlations are represented mathematically in the form of adjacency matrices. The matrices describe important correlations for the scaling function as well as for the transfer function. For the purpose of central access, these matrices are also stored in the database.
The introduction of these matrices is justified by the fact that the available data volume, which describes individual interpolation points, is much smaller than originally assumed. Furthermore, the dimensionality to be considered was significantly higher than assumed, which resulted from the concrete determination procedures of the characteristic values from the descriptor determining processes. Thus, the individual dimensions are sparse from the point of data perspective, which is particularly problematic when using data-driven techniques - the so-called sparse data problem. Due to these two circumstances, it is not possible to reduce the high-dimensional space of the characteristic values in a data-driven way or to choose a starting point. This concerns both the extent of the interpolation points with respect to different alloy systems and the variations on the micro-level in high throughput.
Apart from the storage process, each adjacency matrix also has a version number, which makes the correlations adaptable. This can be done, for example, by new, scientifically relevant results from the respective subprojects or by algorithmically feedback correlation analyses as soon as a sufficient database exists. The initial state of the matrices was determined by extensive expert interviews and first coded by means of tertiary logic within a floating-point number, which can be directly refined, as follows: 0 → "no correlation assumed", 0.5→ "correlation assumed possible" and 1.0 → "correlation assumed". A visualization of these matrices is shown in Figure 1.
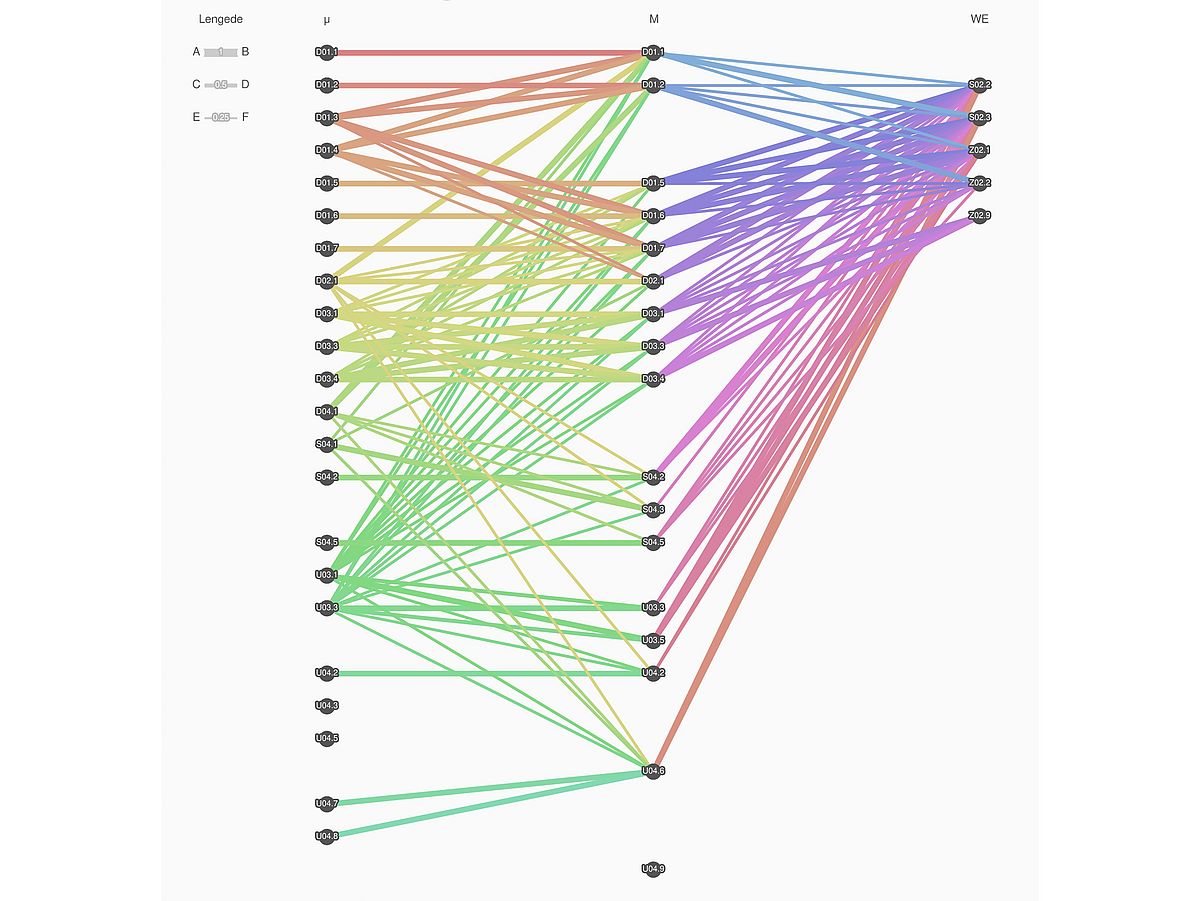
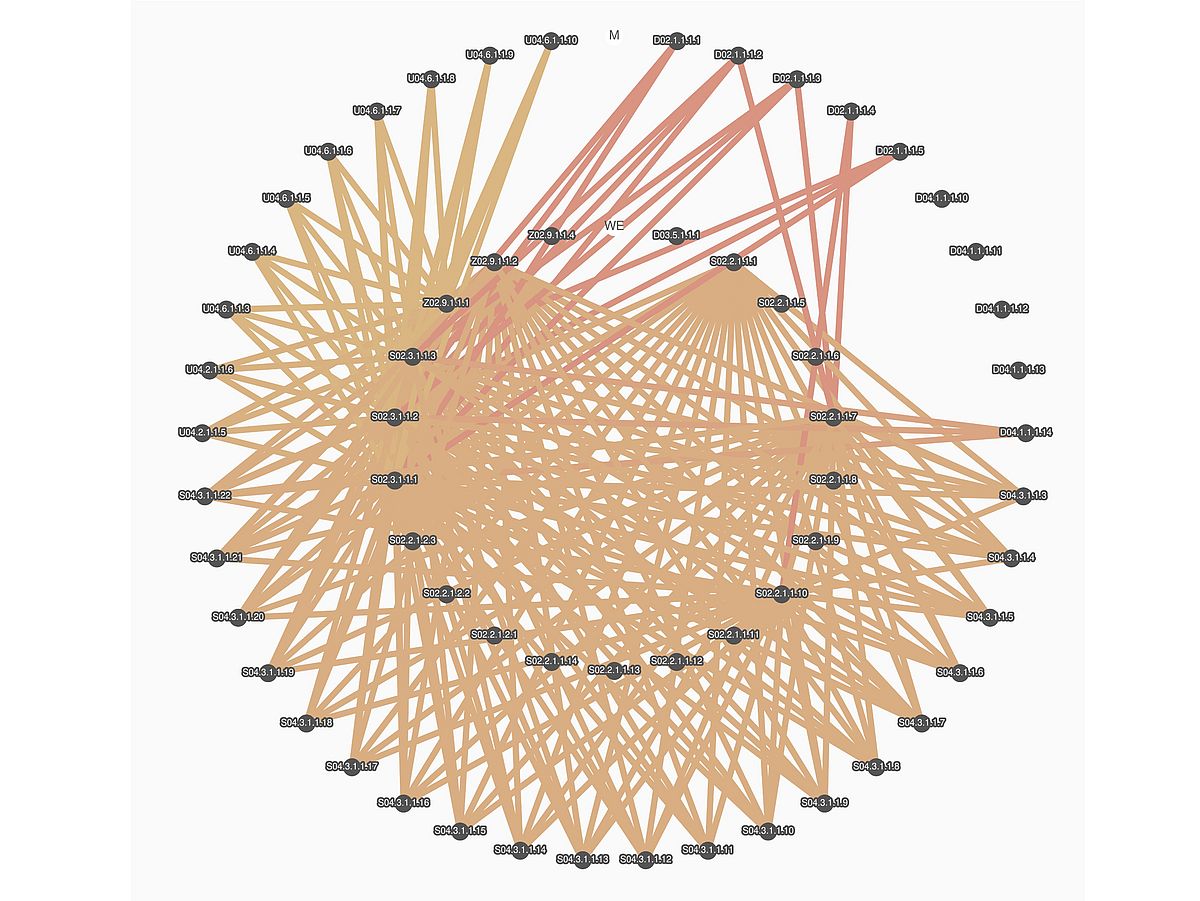
Due to newly developed basic operators, the combination of database, process specification, and adjacency matrices allows it to make queries to the database, which, for example, output specific material characteristics of a standardized tensile test which correlate on the micro level with a specific characteristic value of a falling ball test from the subproject U04 (mechanical treatment). This functionality forms an important basis for the predictor function and the algorithmic implementation of the hypothesis system described below.
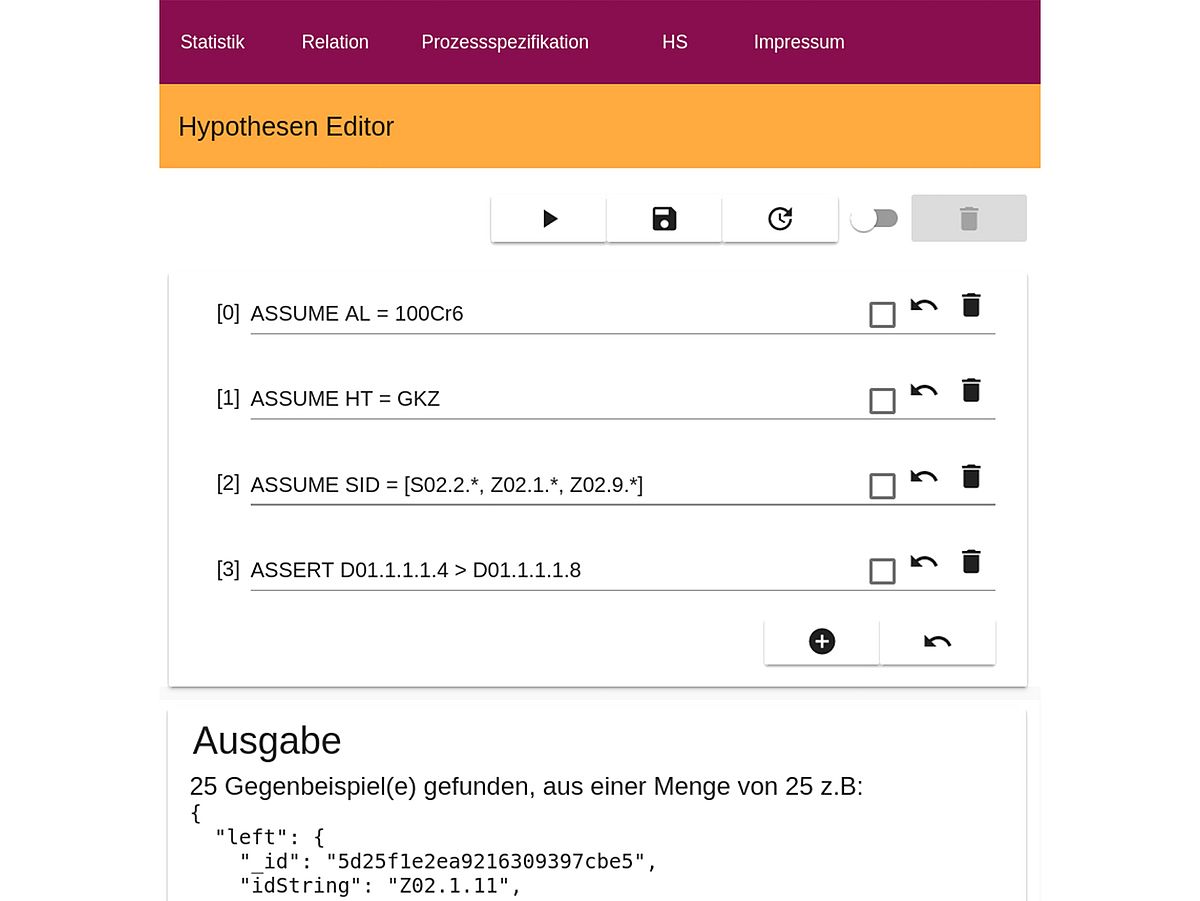

The Hypothesis System
A hypothesis system in combination with a domain-specific language (DSL) has been developed, which allows formulating and evaluate hypotheses about properties of the existing database. The hypotheses consist on the one hand of assumptions and on the other hand of assertions.
The prerequisites are used to define a validity area for the hypotheses. This makes it possible, for example, to apply the assertions following in the hypothesis only to a specific specimen geometry or heat treatment. Apart from that, more complex properties can be described, which refer to information about current correlations (from the adjacency matrices), for which modeling techniques from the field of model checking have been used.
Figure 2 shows the web-based hypothesis editor for formulating new hypotheses that are evaluated in the back-end. Figure 3 shows the supported language constructs of the developed DSL to describe multi-level assumptions as well as assertions that are logically connected. Additionally, the introduced nomenclatures regarding sample and process description as well as the description of a single characteristic value are supported. The common arithmetic operators are available, also in comparison with constants. Besides, more complex characteristics can be calculated on the data series, which for example calculate the Pearson's Correlation Coefficient (PCC) and allow comparing them.
The formulated hypotheses can be validated or falsified by the developed system. In the case of falsification, corresponding counter-examples are shown, i.e. data artifacts for which the outlined assertions are not valid and which therefore refute the hypothesis. A validation implies that the formulated hypothesis is valid for the entire data basis under these assumptions.
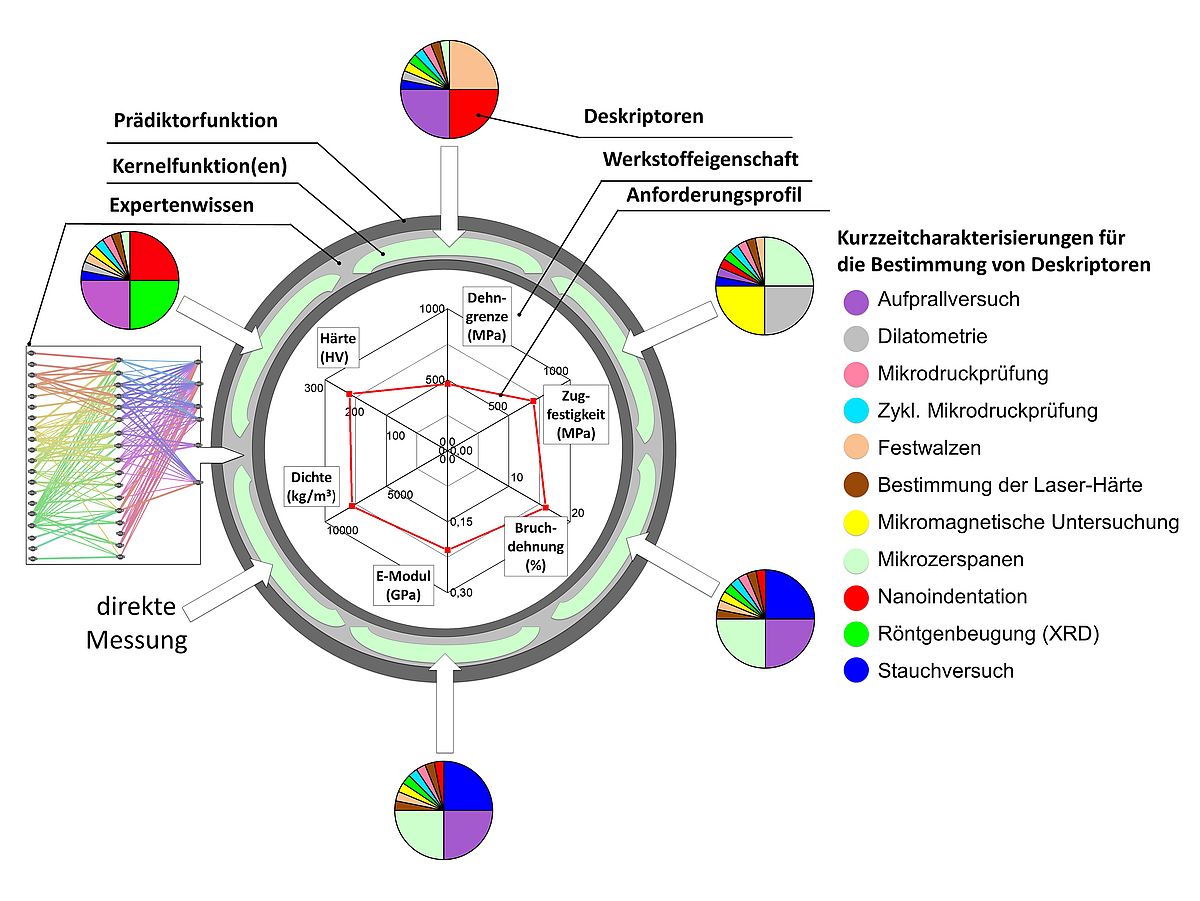
The predictive function
The developed predictor function is an essential aspect of the overall method and is strongly integrated into the overall data flow. The predictor function allows a prediction of the context between the determined descriptors at the micro level and the material properties of the correlated macro samples. For the construction of the predictor function, interpolation points are required which are composed of (a) correlated descriptor determinations at micro and macro level and (b) correlated descriptors as well as material properties at macro level. For this purpose, the data sets (a) are used for the construction of the scaling function, which maps the scale effects between the micro- and macro-level.
The data sets (b) are used for the construction of the transfer function, which realizes the actual prediction of material properties.
The predictor function consists of a composition of these two functions from a functional point of view and has been published at the 10th IEEE Symposium Series on Computational Intelligence (IEEE SSCI 2017). For the interpolation points, the used alloy system, whose investigation was concentrated on the alloy 100Cr6 in the first funding phase, and the heat treatments are elementary. The heat treatment must be carried out in such a way that comparable micro structures are created. The necessary parameters for this were determined in the working group (scaling), specified in the form of a variant plan and included in the process specification.
Apart from that, access to the adjacency matrices is necessary to generate individual so-called kernel functions, which map two input vectors each to a value representing the scalar product of both vectors. According to expert knowledge, each kernel function is valid for a subset of all descriptors and material properties. This segmentation was based on the initially expected correlations and necessary to address the high dimensionality and sparse data problem.
Depending on the structural conditions of the descriptors or material properties used, different kernel functions and parameters, which have to be determined individually, can be used.
A kernel function is instantiated and then trained with the data points of the sampling point, which are extracted from the database by using the basic operators. The procedure provides that the training is repeated after determining further markers. It must be taken into account that the kernel function has a specific state after each training step, which is defined by the calculated parameterization. A kernel function is stored in the developed framework after each training and can be accessed. The predictor function aggregates the results of all kernel functions according to the input for the prediction. The introduction of kernel functions made it possible to realize the so-called Kernel-Trick, which allows representing non-linear data sets in the best possible way by combining several simple regressions. This method was published in the SSCI paper with focus on kernel functions that corresponded to the type of kernel recursive least mean square (KRLMS) techniques, which achieved good prediction results in repeated training steps due to their recursive character. The parameter selection was optimized by the means of cross-validation.
Publications
R. Drechsler, S. Huhn, Chr. Plump: Combining Machine Learning and Formal Techniques for Small Data Applications - A Framework to Explore New Structural Materials. Euromicro Conference on Digital System Design (DSD), Portorož, Slowenien, 2020, [Link to Conference], [Link to PDF]
S. E. Harshad Dhotre, Krishnendu Chakrabarty, Rolf Drechsler: Machine Learning-based Prediction of Test Power, IEEE European Test Symposium (ETS), Baden-Baden, Germany, 2019.
D. T. Sebastian Huhn, Rolf Drechsler: Hybrid Architecture for Embedded Test Compression to Process Rejected Test Patterns, IEEE European Test Symposium (ETS), Baden-Baden, Germany, 2019.
S. Huhn, D. Tille, R. Drechsler: A Hybrid Embedded Multichannel Test Compression Architecture for Low-Pin Count Test Environments in Safety-Critical Systems, International Test Conference in Asia (ITC-Asia), Tokyo, Japan, 2019.
B. Ustaoglu, S. Huhn, F. S. Torres, D. Große, R. Drechsler: SAT-Hard: A Learning-based Hardware SAT-Solver, EUROMICRO Digital System Design Conference (DSD), Kallithea - Chalkidiki, Greece, 2019.
M. Picklum, M. Beetz: MatCALO: Knowledge-enabled machine learning in materials science, Computational Materials Science 2019, 163, 50-62
Huhn, S., Frehse, S., Wille R., Drechsler, R. Determining Application-Specific Knowledge for Improving Robustness of Sequential Circuits. IEEE Transactions On Very Large Scale Integration (VLSI) Systems.
[Link zur Zeitschrift ] [Link zum Artikel]
Huhn, S., Eggersglüß, S., Drechsler, R. Enhanced Embedded Test Compression Technique for Processing Incompressible Test Patterns. 31. GI/GMM/ITG Testmethoden und Zuverlässigkeit von Schaltungen und Systemen. 2019. Prien am Chiemsee, Germany. [Link zum Workshop] [Link zum PDF]
Ustaoglu, B., Huhn , S., Große, D., Drechsler, R. SAT-Lancer: A Hardware SAT-Solver for Self-Verification. 28th ACM Great Lakes Symposium on VLSI (GLVLSI). 2018. Chicago, Illinois, USA. [Link zur Konferenz]
Huhn, S., Merten, M., Eggersglüß, S., Drechsler, R. A Codeword-based Compaction Technique for On-Chip Generated Debug Data Using Two-Stage Artificial Neural Networks. 30. GI/GMM/ITG Testmethoden und Zuverlässigkeit von Schaltungen und Systemen (TuZ 2018). 2018. Freiburg (Breisgau), Germany. [Link zum Workshop]
C. Große, C. Sobich, S. Huhn, M. Leuschner, R. Drechsler, L. Mädler: Arduinos in der Schule - Lernen mit Mikrocontrollern, Computer + Unterricht 2018.
Sebastian Huhn, Heike Sonnenberg, Stephan Eggersgluess, Brigitte Clausen, Rolf Drechsler. Revealing Properties of Structural Materials by Combining Regression-based Algorithms and Nano Indentation Measurements Conference. 10th IEEE Symposium Series on Computational Intelligence (SSCI), Hawaii, USA, 2017 [Link zur Konferenz] [Link zum PDF [PDF] (1.9 MB)]
Harshad Dhotre, Stephan Eggersglüß, Rolf Drechsler. Identification of Efficient Clustering Techniques for Test Power Activity on the Layout. 26th IEEE Asian Test Symposium (ATS), Taipei, Taiwan, 2017 [Link zur Konferenz]
Sebastian Huhn, Stephan Eggersglüß, Rolf Drechsler. Reconfigurable TAP Controllers with Embedded Compression for Large Test Data Volume. 30th IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Cambridge, UK, 2017 [Link zur Konferenz][Link zum PDF [PDF] (255 KB)]
Sebastian Huhn, Stephan Eggersglüß, Krishnendu Chakrabarty, Rolf Drechsler. Optimization of Retargeting for IEEE 1149.1 TAP Controllers with Embedded Compression. Design, Automation and Test in Europe (DATE), Lausanne, Schweiz, 2017 [Link zur Konferenz] [Link zum PDF [PDF] (285 KB)]
Drechsler, R., Eggersglüß, E., Ellendt, N., Huhn, S., Mädler, L. Exploring Superior Structural Materials Using Multi-Objective Optimization and Formal Techniques. 6th IEEE International Symposium on Embedded Computing & System Design (ISED), December 15-17, Patna, India, 2016.
Head
Prof.Dr. phil. nat.habil.
Rolf Drechsler
drechslerprotect me ?!informatik.uni-bremenprotect me ?!.de
associated Head
Prof.
Michael Beetz, PhD
michael.beetzprotect me ?!uni-bremenprotect me ?!.de
Project Management
Sebastian Huhn
huhnprotect me ?!informatik.uni-bremenprotect me ?!.de
Mareike Picklum
mareikepprotect me ?!cs.uni-bremenprotect me ?!.de